Neural Networks and Speaker Classification in Audio
Shamila Jeewantha - undergraduate student , University of Moratuwa

keywords: Neural Networks, Deep Learning, Speaker Diarization
In contrast to cascading methods which often rely on multiple stages such as feature extraction, clustering, and re-segmentation, a unified framework called End-to-End Neural Diarization (EEND) [1] has been proposed to streamline this process recently. This EEND system does not have separate modules for extraction and clustering of speaker representations and uses a single neural network to directly output speaker diarization results. Since clustering-based methods implicitly assume one speaker per segment, it has been difficult to deal with speaker-
overlapping speech which EEND can handle both during training and inference. Furthermore, EEND models can be easily trained/adapted with real-recorded multi-speaker conversations just by feeding the corresponding multi-speaker segment labels compared to other solutions that require clean, non-overlapping synthetic conversational speech for training the model.
There are multiple versions of EEND models that has evolved over time and the first among them is a BLSTM (Bi-directional Long Short-term Memory) based model which has treated the speaker diarization problem as a multi-label classification problem, and introduces two loss functions called permutation-free objective function to avoid the speaker-label permutation problem during training and Deep Clustering (DPCL) loss function, which is used for encouraging hidden activations of the network to be speaker discriminative representations.
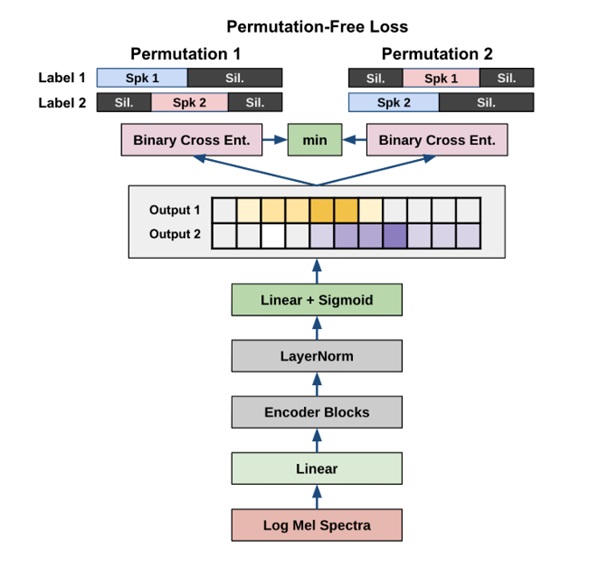
Figure 1: Two-speaker end-to-end neural diarization model with BLSTM [2]
An input to the EEND model is a T-length sequence of acoustic features, with T representing the timeframe. A neural network then outputs the corresponding speaker label sequence for each time frame where ] in which represents the speech activity of the speaker k at the time frame t, and K is the maximum number of speakers that the neural network can output. The Figure 1 depicts how inputs, outputs and internal layers are arranged.
Importantly, it can be output 1 for different k speakers, indicating that these speakers are speaking simultaneously (i.e. over-lapping speech). In general, this nature is preserved across all the EEND models. Changing an order of speakers within a correct label sequence is also regarded as correct which introduces a problem called label ambiguity obstructs the training of the neural network when a standard binary cross entropy loss function is used that prompted the introduction of the permutation-invariant training loss with this model which is another entity that is common with other EEND models as well.
As an extension of the BLSTM EEND model, the SA EEND model[3] was introduced with self- attention based neural network. In contrast to BLSTM, which is conditioned only on its previous and next hidden states, self-attention is directly conditioned on all the other frames, making it much more suitable for dealing with the speaker diarization problem. This enables the model to capture global speaker characteristics in addition to local speech activity dynamics. The model primarily consists of self-attention-based encoding blocks Inspired by the introduced in Speech- Transformer [4] instead of BLSTMs. Two encoder blocks are present in the model with 256
attention units containing four heads which are followed by the output layer for frame-wise posteriors with each encoder block carrying two sub-layers. The first is a multi-head self- attention layer, and the second is a position-wise feed-forward layer. The presence of BLSTM or self-attention layers in EEND models make it difficult to do online processing. Another major limitation is that the SA-EEND and earlier versions fix the output number of speakers, thus, knowing the number of speakers in advance is a requirement. One possible way to treat a
flexible number of speakers with this fixed-output architecture is to set the number of outputs to be large enough. However, it requires knowing the maximum number of speakers in advance, and such a strategy results in poor performance and also the calculation cost of the permutation- free loss increases if we set a large number of speakers to be output.
To cope with an unbounded number of speakers, several extensions of EEND have been investigated and first among them is the extension of SA-EEND called EEND-EDA (encoder- decoder-based attractor). This method applies an LSTM-based encoder-decoder on the output of EEND to generate multiple attractors. To make this method end-to-end trainable, the Encoder-Decoder based Attractor calculation (EDA) has been designed to determine attractors from an embedding sequence. The probability of whether or not an attractor exists to
determined using a fully connected layer with a sigmoid function and the attractor generation stops when the new attractor probability is below a certain threshold. Then, each attractor is multiplied by the embeddings generated from EEND to calculate the speech activity for each speaker. Figure 2 shows the architectural diagram of the EEND-EDA model indicating.
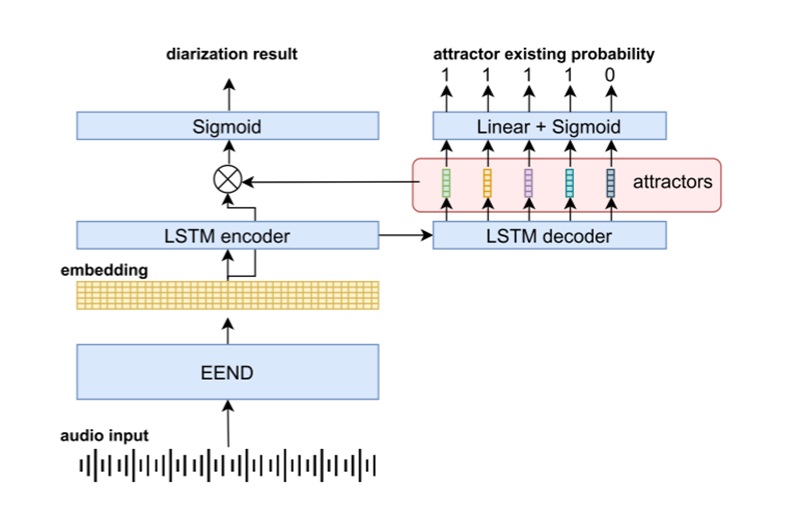
Figure 2 : End-to-end neural diarization with encoder-decoder-based attractor [2]
Further, it has been observed that a larger number of speakers during training does not serve a smaller number of speakers during inference if the training is done on a specific larger number of speakers eventually concluding that the DERs degraded when the number of speakers during training and inference was different. Moreover, it is empirically suggested that EEND tends to overfit the distribution of the training data.
References
[1] Y. Fujita, N. Kanda, S. Horiguchi, K. Nagamatsu, and S. Watanabe, “End-to-End Neural Speaker Diarization with Permutation-Free Objectives,” Aug. 2019, pp. 4300–4304. doi: 10.21437/Interspeech.2019-2899.
[2] T. J. Park, N. Kanda, D. Dimitriadis, K. J. Han, S. Watanabe, and S. Narayanan, “A review of speaker diarization: Recent advances with deep learning,” Comput Speech Lang, vol. 72, p. 101317, 2022, doi: https://doi.org/10.1016/j.csl.2021.101317.
[3] Y. Fujita, N. Kanda, S. Horiguchi, Y. Xue, K. Nagamatsu, and S. Watanabe, “End-to-End Neural Speaker Diarization with Self-Attention,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2019, pp. 296–303. doi: 10.1109/ASRU46091.2019.9003959.
[4] L. Dong, S. Xu, and B. Xu, “Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5884–5888. doi: 10.1109/ICASSP.2018.8462506.
Authors :
Profession: undergraduate student
University: University of Moratuwa

Dr. UthayaShankar Thayasivam
Profession: Lecturer
University of Moratuwa

 to Establish a Resource Pool of Expertise for Research Review and Roadmap Development")
